AI vs. Data Science vs. Data Engineering
Jeremy Karnowski & Ross Fadely

The landscape of technical professions is constantly changing, and the resurgence of work in Artificial Intelligence has opened up new opportunities that differ from traditional Data Engineering and Data Science positions. Data Engineers build data pipelines and infrastructure to ensure a constant availability of transformed data. Data Scientists analyze and build models from these data to develop new product features or drive the bottom line of the business. The goal of newly-formed AI teams is to build intelligent systems, focused on quite specific tasks, that can be integrated into the scalable data transformations of Data Engineering work and the data products and business decisions of Data Science work.
The differences between Artificial Intelligence, Data Science, and Data Engineering can vary considerably among companies and teams. We previously posted on the differences between Data Science and Data Engineering roles, and because these new AI roles differ from both, here we outline the roles for contrast.
AI Professionals
Artificial Intelligence, or AI, focuses on understanding core human abilities such as vision, speech, language, decision making, and other complex tasks, and designing machines and software to emulate these processes. AI has a long and rich history, and while many of the tools and techniques have been around for decades (i.e. multi-layer perceptrons, convolutional neural networks, reinforcement learning), recent advances in high performance computing, the development of distributed methods, and the availability of large labeled datasets have accelerated its adoption in industry. Due to this accelerated growth and success, there is an unprecedented need for AI practitioners across a range of industries.
The types of AI roles vary from company to company and industry to industry. While AI professionals come with many titles (e.g. Deep Learning Engineer, Computer Vision Researcher, Machine Learning Engineer, and NLP Scientist), they all share the same focus: building complex, state-of-the-art models that tackle specific problems.
Building these systems requires strong knowledge of engineering and machine learning principles, and depending on the team or product, some roles may weigh heavier on specific skills. For instance, some AI roles are more research focused and concentrate on finding the right model to solve the task, while others are more focused on training, monitoring, and deploying AI systems in production. Projects often center around questions like: How can we encapsulate subject matter expertise in order to augment or replace complex time-consuming decision making tasks? How can we make our automated customer interactions more natural and human-like? How can we uncover subtle patterns and make decisions that involve complicated new types of streaming data?
While there is a spectrum of AI focused work, almost all practitioners regularly prototype new AI system architectures, including building end-to-end pipelines. This means they need to stay current with the latest (often academic) advancements in AI. They actively monitor the performance and training of systems, help scale them up for production, and iterate on systems given shifts in data and/or model performance. AI Professionals typically have a good working knowledge of the python Data Science stack (e.g., NumPy, SciPy, pandas, scikit-learn, Statsmodels, etc), employ one or more deep learning frameworks (e.g., TensorFlow, Theano, Torch, Deeplearning4j, etc), and sometimes leverage distributed data tools (e.g., Hadoop, Spark, Flink, etc).
Data Scientists
Roles of Data Scientists in industry vary considerably. Organizationally, Data Scientists are often interfacing with internal (and sometime external) teams to help direct decisions which drive business. This involves answering questions like: How do we better understand and serve our customers? What ways can we optimize our operations and product? Why should we roll-out a new feature or product?
Frequently, Data Scientists are also directly involved in building data products. These products are everywhere, integrated into the websites and apps we use. Classic examples include Facebook’s custom user-based news feed and LinkedIn’s “People you may know” feature.
The day-to-day for data scientists may involve cleaning and manipulating lots of data, scoping and testing out high ROI projects, building out customized algorithms, and communicating results to the team and company clients. Data Scientists typically use Python or R, make heavy use of SQL queries, do analyses in Jupyter notebooks, and often have some data visualization experience in one or more frameworks.
Data Engineers
The amount of data businesses are ingesting and serving is trending in one direction: UP! In order to enable the functionality of data teams and products, engineers must design robust and scalable data architectures. Engineers who construct these systems have to think carefully about the current and future demands the business will need. What compromises need to be made for different ingestion/serve rates? Do we need to provide real-time streams to customers? How do we efficiently query the data? How do we keep track of vital metrics?
Along with these increasingly demanding needs is a landscape of data tools which is constantly and rapidly evolving. Deciding between tools like Spark, Flink, Kafka, Cassandra, Redshift, and ElasticSearch is a difficult and challenging task. Skilled Data Engineers not only know the pros and cons of using one tool over another, but also know how to implement them in production systems.
As a result, the main daily activities of Data Engineers involve building out data systems to solve new project challenges, improving and maintaining existing architectures, integrating systems with new/better tools, and syncing with team members to ensure quality work and product flow.
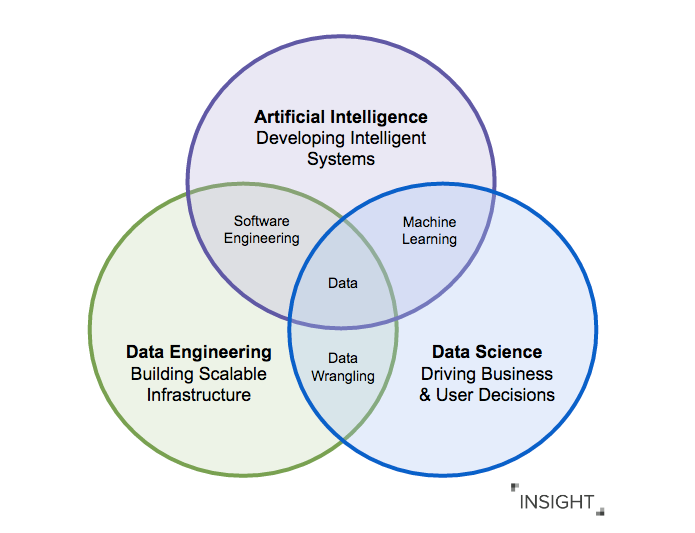
Overlap
Distinguishing between specific instances of the roles is often not clear cut. Many Data Science roles often need to know modern Data Engineering tools to get the data they need, while more and more Data Engineering roles are performing significant analyses and incorporating machine learning in their pipelines. There is also a significant overlap between the work AI professionals do and that of Data Scientists and Engineers. The core ideas and knowledge that drive the analyses of Data Scientists underpin the skills needed to build AI models. These models typically require very large datasets, so while efficient manipulation and use of large amounts of data is a fundamental aspect of Data Engineering work, it is crucial for state-of-the-art AI systems.
In our view, the fundamental difference between AI and Data Science/Engineering is in the nature of AI’s primary goal: to build intelligent systems that generate their own features and knowledge of a domain, and deliver performance on tasks which is near, at, or above human expert level. This aim naturally requires a different and/or additional set of skills, focused on models and techniques which marry the cutting edge of AI research and practice.
(This post was originally hosted on Medium)