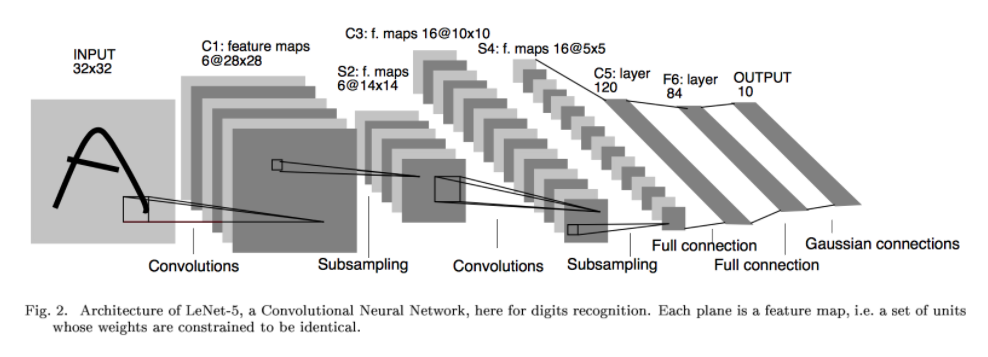
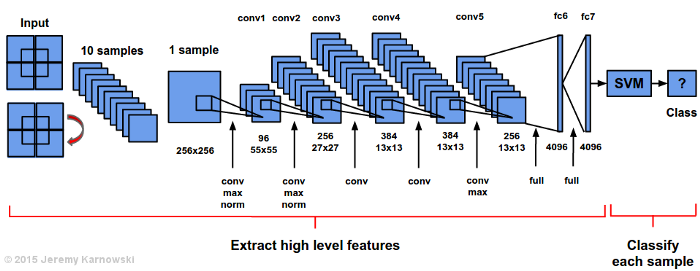
by Rose Hendricks (originally found here)
While finishing his dissertation, Jeremy became an Insight Data Science Fellow, participating in an intensive post-doctoral program to prepare academics for careers in data science. Because he was such an all-star during the program, Jeremy is now a Program Director and Data Scientist for Insight Data Science. In this podcast, I talk to him about his experiences at Insight Data Science. He shares some of the features of his PhD training that have helped him in his data science quest and other skills and modes of thinking he’s had to develop since beginning to work in industry.
Enjoy!
Podcast available here (transcript below)
— — — — –
Rose: Hello! And welcome to UCSD Cog Sci’s very first podcast. I’m Rose Hendricks, and I’m here today with Jeremy Karnowski, who is finishing up his PhD in our department, and is here to talk to us about some of the things he’s been doing in the recent past with Insight Data Fellows, and the path he’s taken from PhD student into the working world. Jeremy, thanks so much for joining us!
Jeremy: Thanks for having me.
Rose: First, I’m hoping you can tell us: You completed a program called Insight Data Fellowship. The one sentence I got about that from their website is that it’s an intensive, seven-week post-doctoral training fellowship that bridges the gap between academia and a career in data science. Can you explain to us a little bit about that?
Jeremy: Yeah. As you mentioned it’s a seven-week program. People that are finishing up their PhDs or post-docs and have been doing a lot of quantitative work in physics, or bio-statistics, or computational social sciences, it’s a way for them to make that last little leap into industry. The idea is they’ve already being doing data science in academia, but they’re trying to find roles doing the same thing for companies, either in the Bay area, New York, or Boston.
Rose: Cool. I feel like “data science” is one of those phrases we all toss around, and of course we’re all doing science of some form and dealing with data of some form, but what do people really mean when they talk about data science?
Jeremy: Data science could be a couple different forms. This is some of the problem with people that are coming from academia and trying to transition into industry because the field is so broad that data science could mean many different things. Especially, say, in the Bay area. You could have things that are more from a business intelligence standpoint, or you could have people that do analytics where they’re trying to understand some of the insights that are in data at a company or doing some data mining, some people focus on machine learning, some people really focus around building data products, where you’re making some product for consumers or someone inside of a business, but does a lot of data in the back end that’s being useful for that. One really simple example would be “people you might know” on LinkedIn — there’s a lot of interesting graph relationships that are going on, it’s very data-driven, but then there’s a product on the front end that people can just use. They come to it, they find some way to connect with someone, and it’s something that’s real, but there’s data in the back end.
Rose: Sure. So if you project yourself back one year, you were in San Diego, working on your PhD. Maybe it wasn’t just one year ago, but what got you interested in data science in the first place? What was your path to finding Insight Data Fellowship?
Jeremy: I was in one lab in the cognitive science department, and it was very computational. And I switched and I was still doing something computational, but I was shifting my focus. I joined a lab that really had a large amount of audio and video data that no one was diving into. At that time, I was getting the sense that trends were going toward large data and machine learning, lots of different ways of dealing with massive amounts of data. I was like, well, this is probably going to be not only great for studying something in the department, but also building up skills for entering a different sort of work force. I would say — remind me again, what was the second part?
Rose: Just thinking about your transition, or, it seems like your back and forth with one foot in academia. How did you start? Certainly you needed new skills, I’m guessing.
Jeremy: You’d be surprised! Just — a lot of people that come out of PhDs or post-docs that go into Insight Data Science, they have already been doing data science, usually large-scale data analysis, in their PhD, so that sort of fits the bill. Often times they might not be using the exact toolkit that is in industry. Some people that come from physics are using a variant of C++ that does different things and a lot of physics packages are built into that. A lot of people, as you know, in neuroscience and computational social science use Matlab, so that’s not really industry standard, so making sure you’re up to speed with Python or R, and using the toolkits in those packages, is always a big plus. And I think other things that I jumped on board with… I really wasn’t clear about data science when I started my journey. I was thinking that I should probably go into software engineering or something, so it was really unclear. And those interviews were very different, and I was learning a lot about algorithms and data structures and doing coding problems. I went to a couple different interviews and it just didn’t seem right. It actually was really fortuitous because I talked with a friend. It was basically a friend of a friend. I talked with him and he had done a math PhD and looked into software engineering jobs, and then also had explored the data science space. And he was chatting with me about the role I was looking for and what I wanted to do in industry, and he was like, you should definitely check out data science, that’s where it’s at. And immediately as I started looking at those jobs, those were the sort of businesses that called me back and were interested because that’s the skill-set you have when you’re doing quantitative social science.
Rose: That leads into my next question, which is about some of the skills you developed during your PhD. Maybe not even tangible ones, maybe soft skills, that have helped you make this transition now into data science.
Jeremy: So I think, one of the things that’s very different from industry in academia is the time scale of things in academia could be months or years, and it’s really about perfecting something in a very small niche. And you’re spending a lot of effort to get there. And in industry, the timeline’s very different. Everyone’s working on several-week timelines to push something out. Or maybe you need this analysis in the next few days to make something happen. It doesn’t have to be 100% correct. Often times you really need to get 80 or 90 percent of the way there really quickly just so you can get a sense of how do you move a business in one way or another. That’s a very different skill than how academics do things. I think another thing that’s really important is trying to speak to the consumers or anyone using the product or different people in the organization. Academics are very used to talking with other academics. There’s lots of lectures and lots of talks and everything’s at a high level. It’s really important to be able to speak about really complicated topics at a high level and explain them to different parts of the company. I always found the cognitive science department really good for that because we have a lot of interesting and very in-depth research, say, neuroscience or psychology, or more computer science labs, and they all have to explain their research to each other, and having that skill is very important. And thirdly, I think another important thing is a lot of the data in data science organizations, they are fundamentally about people. There are people using the products. There are people interacting in the businesses. And a lot of the things you want to capture about how your product is being used is about human behavior. I think that is something that’s also a very different skill to learn because even though you’re doing the same sort of analysis, like say you might be doing something in bioinformatics or physics, you start thinking about the data in a different way.
Rose: That’s really interesting. It sounds like you’re saying maybe there are some ways of thinking that are valued in academia, but aren’t in the same way in industry, and at the same time, so many of those skills you cultivated over the course of your PhD are still really meaningful. Is that sort of along the lines…?
Jeremy: Yeah. There are definitely differences. The kinds of data you deal with could be very instrumental to… Say if you’re doing quantitative social science, or something where you’re studying people. That could be very helpful. If you’re doing things with — Even people who are studying say, for instance, EEG signals: you’re collecting data from lots of different small devices and trying to analyze that signal for some reason, and that’s still very data-science-like. But that data’s very different from the data you’d be collecting in industry. So sometimes you need to change up how you think about the data, sometimes you don’t. Thinking about the data might lend itself in different ways to what you might do down the line. I think the skills that are always really important for doing things in PhDs — You learn really quickly you hit your head against problems that are really frustrating for a long amount of time. You’re coming up with the right kinds of questions to ask, you’re testing it, you’re really driving home on things week after week. I think that is something that’s really hard to get if you’re trying to dive into data science and you haven’t had the experience of doing something like this for many years. So that’s a general PhD-level skill that I think is very transferrable. A lot of the very academic things, staying really in the details or taking a really long time to explain something or using a lot of jargon doesn’t work very well when you’re talking with someone, say, from the marketing department. Or maybe you’re doing some data science for marketing purposes and you have to explain to whole teams why what you’re doing matters and how it’s going to change the business. You can’t just use technical terms all the time.
Rose: So you did this seven-week program with Insight Data Science and you’re still at that company, is that correct?
Jeremy: Yeah.
Rose: So can you tell us a bit about what you do now? Maybe at both the high level and the more detailed aspect?
Jeremy: Yeah, sure. So at Insight, after the fellows go through the Insight Data Fellows program, they get call-backs from different companies about places they might want to be placed. And we work really hard to make sure every fellow is getting a job, so we’re with them until the end. And I think I had a lot of call-backs from different places, but at the same time I had sort of had a really great experience with them. And they invited me onto the team. So this was not standard, but it very much fit in line with my career goals. A lot of the things we do at Insight as program directors and data scientists is what you would expect from someone who’s doing a more senior data science role or a head of data science role. So that was really appealing to me. In my role, there are a couple different things. There’s work that’s going on on the back side that’s more about the data that we have and doing more technical work, but really a lot of my job is working with the fellows who come through the program, providing technical guidance, helping them think through their problems. So it’s a mixture of making sure they can get their projects done on time, talking with companies in the Bay area, and also helping provide — Making sure that no one is blocked on anything, that fellows can move forward in their ambitions and projects.
Rose: Wow, so you’re almost paying it forward and getting paid to do so, it sounds like.
Jeremy: Yes, it’s a great job. I think, I like the idea of being in academia, I like the idea of being in industry. I get to be a little bit of both. I get to be in data science and help people push their careers forward as well.
Rose: That’s cool. So I’m wondering now, I asked you earlier to project yourself backward one year, but if you go back even a few more, to maybe when you were like in your second, third, fourth year at UCSD, are there any things you wish you could go back and tell yourself?
Jeremy: Yeah! I think one thing that I would imagine is really trying to understand the landscape of different tools and technologies to tackle a problem. It’s very easy to start from scratch and have an adviser or other grad students tell you these are the ways to do these different things, but then really trying to sample all the stuff that’s out there to understand, if I get this sort of problem, what are all the tools that I could bring to bear to tackle that problem? I don’t know if everyone does that enough. I think another thing that I would suggest, I really wish I would have taken this data mining course that was in the computer science department. At that point I didn’t have to take any more classes and I think that it would have been a really great class to take because that’s really fundamental in a lot of the analytics and things that are going on in the Bay area or in data science in general. I think just taking more courses where you do projects and you’re really trying to get deep into, “What can I do with this data to get to a goal?” I think would be important. Other than things I wish I had done, I actually did get a lot of really great advice. I was in my third year and I was talking with Seana Coulson and Marta Kutas, and I had been transitioning labs. I was going from modeling human decision making and I was switching into modeling multi-agent decision making. So lots of artificial agents making decisions with each other on some sort of task, so distributed artificial intelligence. The advice I got was, this is great, and it’s modeling, and there’s these scenarios that you’re creating, but it would be better if you were able to actually study real-world systems and understand what is actually going on in the real world with systems and agents interacting with each other. And that’s actually how I jumped on the project that did have a large amount of audio and video data because it was all about dolphins interacting with each other and trying to understand their activity. And that was like a real-world system. And I think that was really fundamental in how I started shifting from one career to the next, because it made it much more relevant. And I think if people are in the clouds too much, trying to focus in on real phenomena and understanding them and explaining them is a really important thing to learn.
Rose: I have one more question for you before we finish up because I’ve asked you to project yourself back a few times. So now, naturally, I’d like to go the other way. I’m curious, what are some of the things on your mind for the future? Whether it’s short term, you can tell me what you’re going to do this weekend, or longer term, like things you’re excited about, either in your own life or the whole world. Tell me everything.
Jeremy: I have been really excited about the trends of development. Everyone’s releasing open toolkits for deep learning or artificial intelligence. That’s definitely something I’ve been exploring and trying to get more of a grasp on. Companies have a very large amount of data, and so they’re comfortable with releasing the tools to deal with that because the data is the gold that they’re using. So I’ve been really interested in exploring that space. Another goal I had being out here in the Bay area is I really wanted to see how companies run, see how companies start and form, so that’s interesting as well. And also, getting to the point where trying to lead a team of data scientists at a company and move a business forward. One thing that always surprised me at Insight is that, this was sort of my five-year goal. And I would meet a lot of alumni that would do Insight Data Science, and they were like, “Oh, I did Insight two years ago, and now I’m the head of this data science team, or I lead the data science team at this company.” And I was like, that’s two years! I was expecting it to be five years. So I think anything I say is probably going to happen much quicker than I expect. That’s just how industry works compared to academia. Things are moving so quickly and I don’t even quite know what’s going to happen in the next year or two.
Rose: Well, that’s exciting!
Jeremy: I enjoy it. I try to maximize for the largest number of possible options in the cool and interesting areas, and just keeping doing that, that way everything’s on your plate and open to you.
Rose: Is there anything else that you were hoping to share that I haven’t yet asked you about today?
Jeremy: I would say other than, we’ve been talking a little bit about Insight Data Science in Silicon Valley over in the Bay area, but we also have lots of programs in New York, Boston, there’s a remote program. We also have a data engineering program in the Bay area, and New York. And we’ve had a health data science program in Boston and our first health data science program in Silicon Valley is going to start September.
Rose: Wow, so it’s really exploding.
Jeremy: Yeah, it’s pretty great. We have a lot of great companies that we partner with. And there’s lots of very exciting domains that are branching out. It’s a very exciting time.
Rose: So Jeremy, if people want to find you on the internet, do you have a twitter handle we can share?
Jeremy: I do! It’s @mwakanosya, which sounds really strange. It’s M-W-A-K-A-N-O-S-Y-A. And there’s a whole other story to that! Someday I can tell you if they want to hear it.
Rose: Thanks so much for chatting with me. And I’m sure this will be a pleasure for all the listeners.
Jeremy: Yeah, definitely connect with me on Twitter, I’m happy to chat on LinkedIn. I’d love to chat more and help people out in any way I can.
Rose: Thanks Jeremy!
Jeremy: Thanks very much!